接上一篇DCGAN手写数字生成,虽然它能够生成效果不错的手写数字图片,但它有一个缺点就是不能生成指定数值的数字,好在有一种 GAN 模型叫 cGAN,即 Conditional Generative Adversarial Nets, 出自 此篇论文,它能够生成指定数值的数字图片。
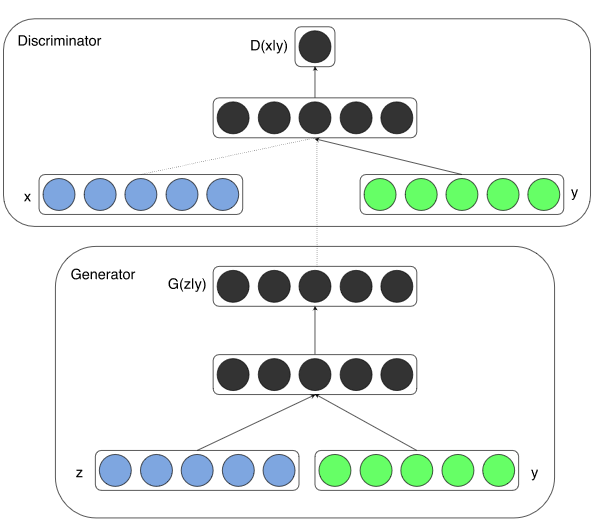
模型结构如下图:
其损失函数定义:
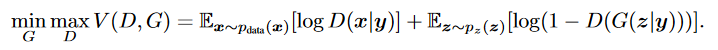
GAN 所能接受的 条件 y 种类很多,如label等等。 接下里,我们就使用 MNIST 数据集加入 label 条件,实现一个可以生成指定数值的数字图片模型。代码实现和上一篇几乎一样,只不过加入了label。废话少说,show me your code:
1、定义生成器
和上一篇中的生成器定义一样,只不过这里的输入维度变成了 110 ,随机噪声的 100 维 + one-hot 编码的 10 维 label ,将两者级联起来送入生成器,生成一个 28*28*1 的黑白数字图像。
级联:tf.concat((step_noise, labels), axis=1)
1 | def make_generator_model(): |
2、定义判别器
判别器的结构也和上一篇的一模一样,不过这里的输入维度由 28*28*1 变成了 28*28*11,将 one-hot 编码的label 条件添加到图片中。具体级联操作:
labels = tf.reshape(labels, (256,1,1,10)) * tf.ones((256,28,28,10)) #[batch, 28, 28, 10]
tf.concat((images, labels), axis=3) #[batch, 28, 28, 11]
1 | def make_discriminator_model(): |
3、定义生成器和判别器的损失函数
损失函数和上一篇的一模一样,不用改,具体如下:
1 | cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) |
4、定义优化器及训练过程
和上一篇 DCGAN 的一模一样,在训练过程中,每次生成一个维度为 [256, 100] 的随机噪声矩阵,级联 labels 条件后喂入 generator 生成 generated_image。
1 | # 实例化模型 |
5、开始训练
此部分还是和上一篇的一模一样,checkpoint 定义要保存的模型对象,这里保存了生成器,判别器及两者各自的优化器,每 20 轮保存一次。
1 | # 保存检查点 |
其中,generate_and_save_images 函数和此前的还是一样,只不过这里喂入的数据,是固定的noise_image 和 noise_label 级联后的维度为 110,来查看生成器生成图片的效果。0--9 的 label 每样是 10个,一共100 个样例。具体实现如下:
1 | noise_image = tf.random.normal([10, 100]) |
1 | def generate_and_save_images(model, epoch, input): |
6、效果展示
每次训练生成的数字效果图如下:

可见,该模型成功生成了label(y) 所指定数值的数字手写图片。为了对生成过程有个动态的直观感受,我们使用如下函数,将每轮训练由固定的 noise 生成的效果图做成一个 gif 图片。
1 | def gif_animation_generate(): |
最后的效果图:
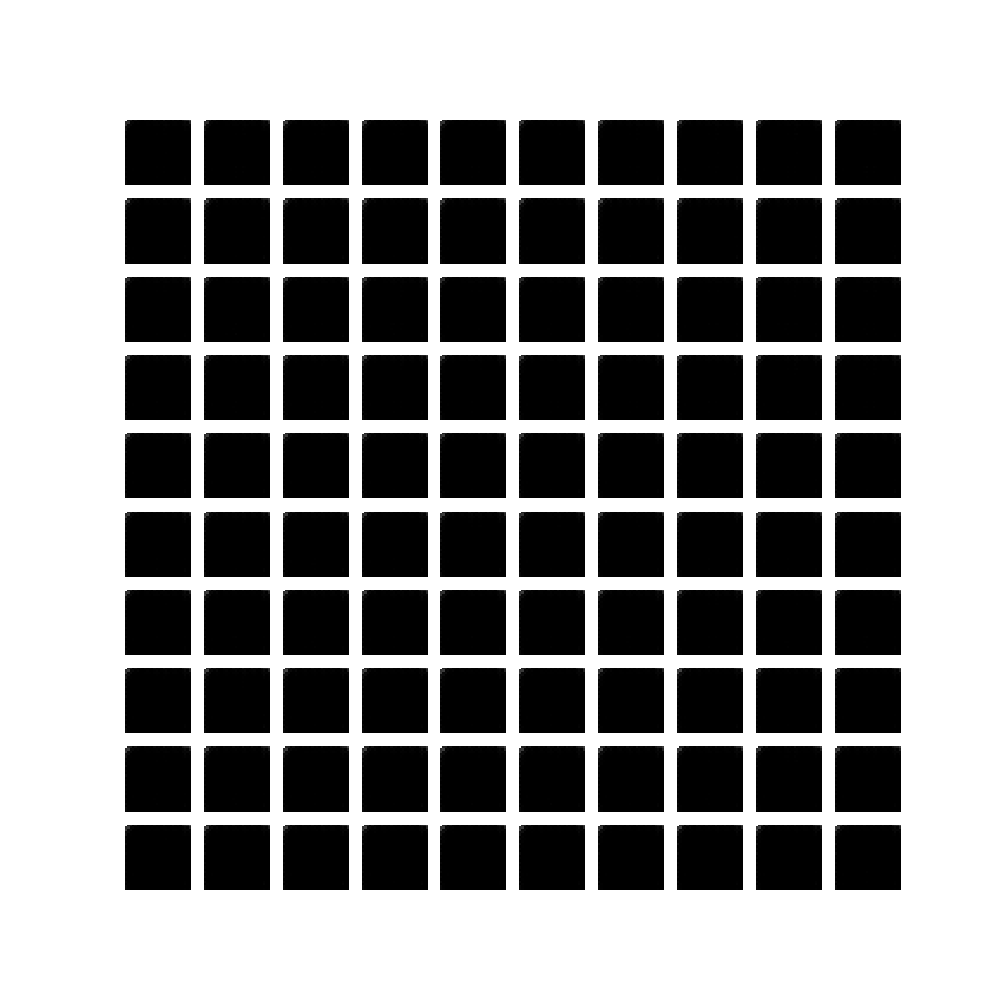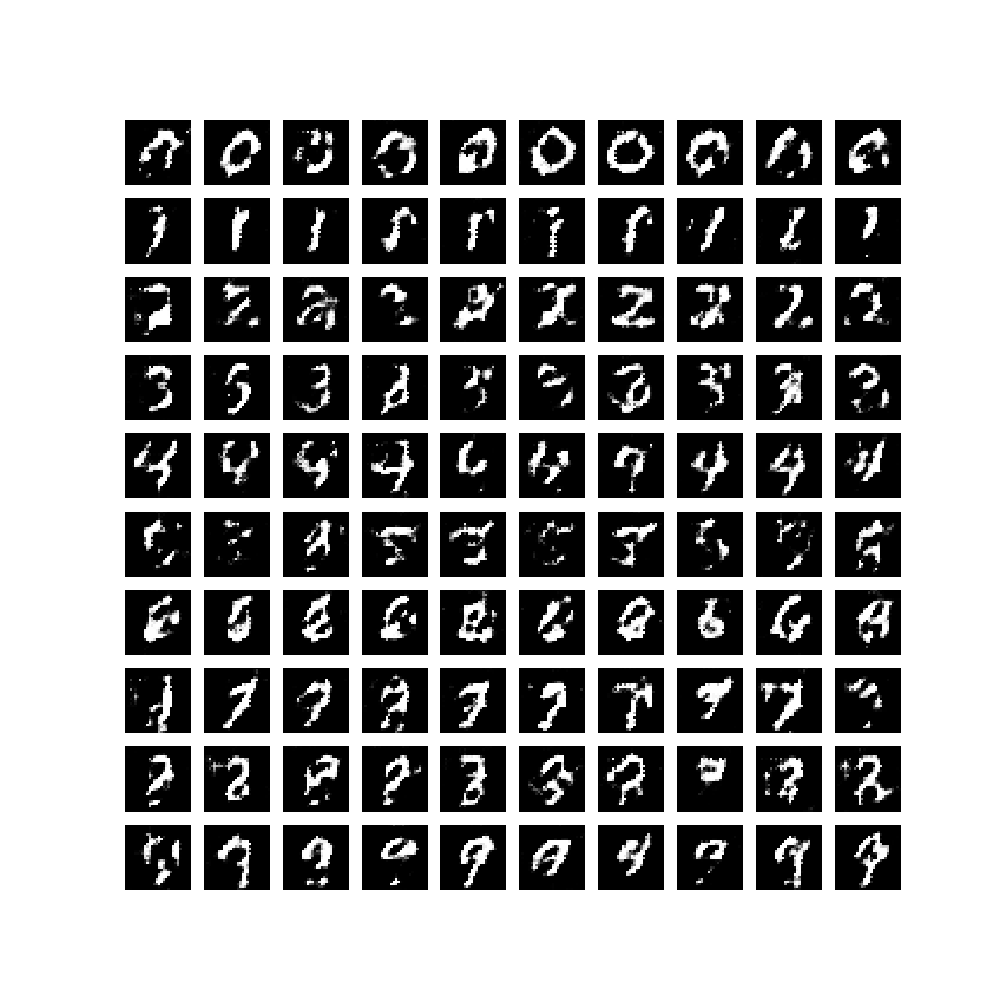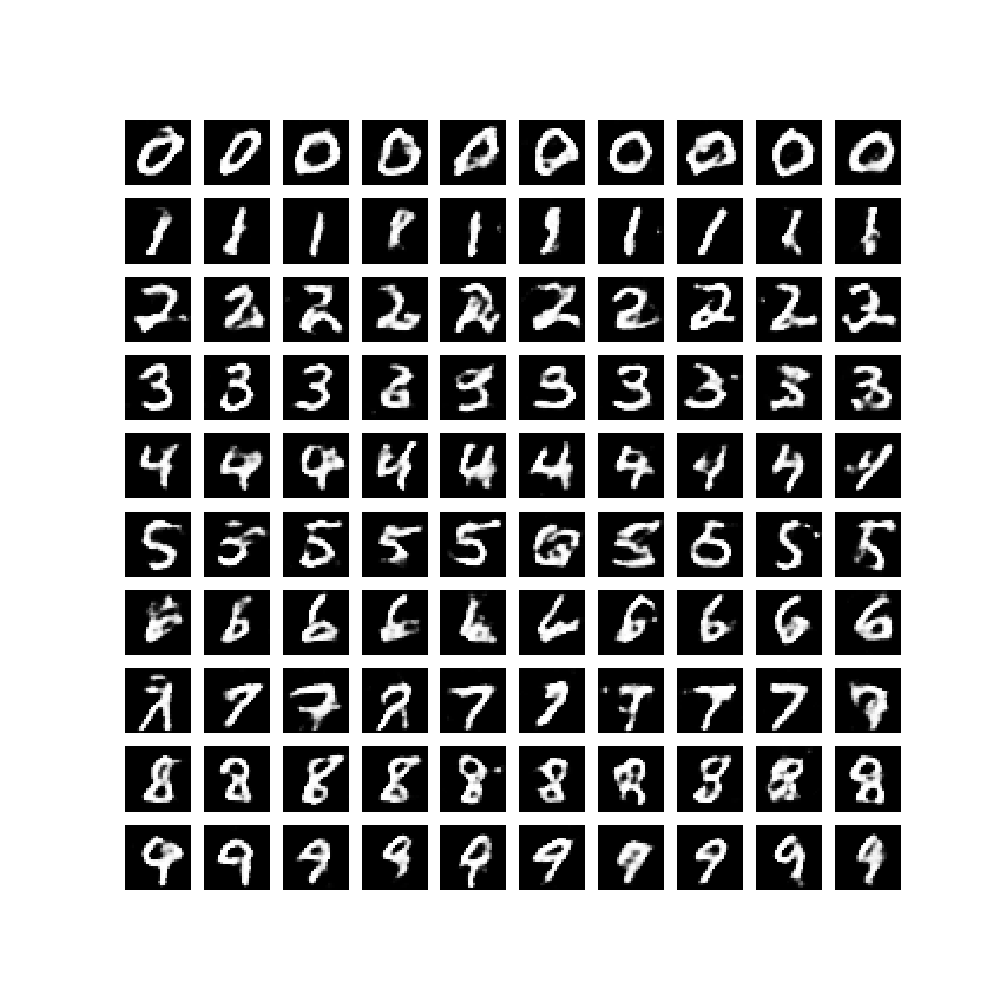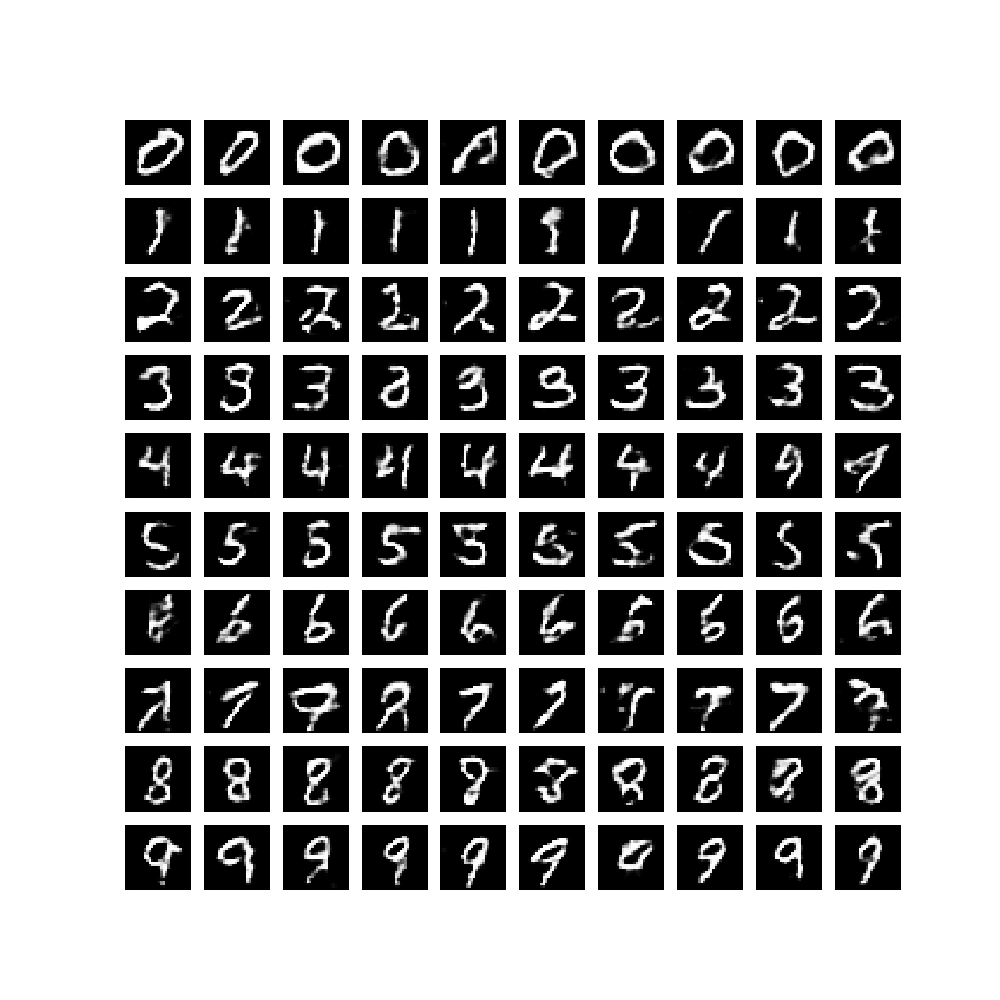
全部代码如下:
1 | # _*_ coding: utf-8 _*_ |
