最近忙里偷闲,补一发之前落下的关于一些GAN的tensorflow2.0实现代码。
首先,GAN ,即生成对抗网络Generative Adversarial Network,由一个生成器Generator和一个判别器Discriminator组成,两者属于 零和博弈 的双方,不是你死就是我亡的状态。
其损失函数一般定义如下:
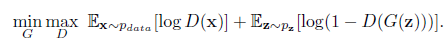
判别器 D 对来自真实数据集的样本 $x\sim p_{data}$ 要输出大概率,越接近 1 越好;对来自生成器生成的样本$z\sim p_z$ 要输出小概率,越接近 0 越好。当然,这是一个零和博弈,对于生成器G来说,其目标与D截然相反,他想使自己生成的样本不能被D识别出来。这么不断的你来我往,双方各自不断调优,最后达成一个平衡状态。
当然,这其中的损失函数也不只这一种,比如说,生成器的损失函数可以定义为:生成样本分布与真实样本分布的 KL 散度值等。
KL 散度用来衡量两个分布之间的相似性。
接下来,我们用很熟悉的 MNIST 的数据集,来实现一个简单的 DCGAN 模型Deep Convolutional Generative Adversarial Networks。该模型由此 论文 提出。其实就是生成器和判别器用深度卷积来实现的。话不多说,上代码:
1、加载数据
MNIST数据集有很多种格式,这里我们使用的是 npz 格式,用 numpy直接解析就可以了。将训练集和测试集联合起来,一起喂入模型进行训练,label用不到,就直接舍弃掉得了。
1 | data = np.load("dataset/mnist.npz") |
2、定义生成器
生成器要做的就是将一个 100 维的随机噪声向量,变换成一个 28*28 的黑白数字图片。用到的是一个全连接层 + 3个反卷积层。
反卷积的具体操作过程见 知乎博文 ,其实就是根据 stride 的值先填充(包括矩阵的左侧和上侧),然后再做步长为 1 的正向卷积。反卷积只能恢复尺寸,不能恢复数值。
1 | def make_generator_model(): |
3、定义判别器
判别器要做的就是对来自真实数据集中的样本输出大概率,对来自生成器的样本输出小概率值。包含两个卷积层和1个全连接层。
1 | def make_discriminator_model(): |
4、定义生成器和判别器的损失函数
其中,生成器损失函数要对fake_output的判别输出与全 1 矩阵做交叉熵,与判别器要做的正好相反。
1 | cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) |
5、定义优化器及训练过程
在训练过程中,每次生成一个维度为 [256, 100] 的随机噪声矩阵,喂入 generator 生成 fake_image。
1 | # 实例化 generator 和 discriminator |
6、开始训练
checkpoint 定义要保存的模型对象,这里保存了生成器,判别器及两者各自的优化器,每 15 轮保存一次。
1 | seed = tf.random.normal([16, 100]) # 查看生成器效果用的 |
每个 epoch 训练结束,我们使用一个固定的 seed(256*100)来查看生成器的生成数字的效果,其查看效果函数定义如下,就是将seed喂入生成器,将生成的数字图片画出来:
1 | def generate_and_save_images(model, epoch, input): |
5、效果展示
每次训练生成的数字效果图如下:

为了有个动态的直观感受,我们使用如下函数,将每轮训练保存的效果图片生成一个 gif 图片。
1 | def gif_animation_generate(): |
最后的效果图:

全部代码如下:
1 | # _*_ coding: utf-8 _*_ |
