第一次作业:点击下载
怎么说,对这门课就是默默告诉自己,习惯就好。默默贴个 github 地址:
https://github.com/justmarkham/DAT8
第二次作业:点击下载
同样,还是贴几个github链接地址:
https://github.com/lamalor/ds100/blob/182feda62685b0988f4b4afb52c85256f4ac7d92/hw6/hw6.ipynb
https://github.com/Dhanush123/data100/blob/master/hw6/hw6.ipynb
1、更改juypter默认工作路径
在 anaconda prompt 中执行命令:
1 | jupyter notebook --generate-config |
即可查看 jupyter_notebook_config.py 配置文件的位置,打开配置文件 jupyter_notebook_config.py,搜索关键字 notebook_dir ,将值设置为自己想要的工作目录并取消注释即可(注意路径中不能有中文);
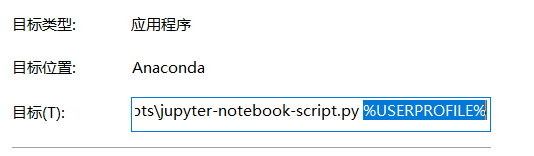
然后右击 jupyter notebook 快捷方式,将属性中的 “目标” 字段的值,去掉末尾的 %USERPROFILE% ,点击 应用,确定即可。
2、jupyter使用anaconda虚拟python环境
打开 anaconda prompt,激活之前创建的某个python虚拟环境,在当前虚拟环境中执行 conda install nb_conda。重启 juypter notebook 服务器即可出现想要的虚拟环境 kernal 。
3、jupyter两种工作模式及其快捷键
- 分为命令模式(边框蓝色) 和 编辑模式(边框绿色)
- 命令模式中,
M进入markdown编辑模式,Y进入代码编辑模式
4、代码自动补全
注意,下面的所有操作是在 base 环境中安装的,在其他虚拟环境中安装好像并不起作用。
安装nbextensions
1 | pip install jupyter_contrib_nbextensions |
安装nbextensions_configurator
1 | pip install jupyter_nbextensions_configurator |
重启 jupyter,在弹出的主页面里,能看到增加了一个Nbextensions标签页,在这个页面里,勾选Hinterland即启用了代码自动补全。
5、pandas教程[pan(el)-da(ta)-s]
1、pandas中的数据分为三种: 一维数据 Series、二维数据 DataFrame、以及三维数据 Panel。
Series相当于一个字典。
1
2
3data = np.random.randn(5) # 一维随机数
index = ['a', 'b', 'c', 'd', 'e'] # 指定索引
s = pd.Series(data, index)二维数据,1. 带Series的字典 2.列表构成的字典 3.带字典的列表
1
2
3
4
5d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])} #one做列
d = {'one' : [1, 2, 3, 4], 'two' : [4, 3, 2, 1]} #one做列
d = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}] #a,b,c做列
df = pd.DataFrame(d) # 新建 DataFrame
print(df)
列的选择,添加与删除
df[‘列名’] df.pop(‘列名’) df.insert(添加列位置索引序号, ‘添加列名’, 数值)
行的选取,列的选取,块的选取
1 | df.index df.columns df.values df.values df.describes() df.T df.dtypes |
python中使用 type(var) 查看变量的数据类型
6、juypter显示行号
view >> toggle line numbers
