21、合并两个有序链表
两个有序链表的合并,本渣代码充分利用原有空间,没开辟新的内存存储新链。
1 | /** |
22、括号生成
生成的种类数是个卡特兰数,因此 n 的值不会太大。卡特兰数在计算机中是个特别重要的数串,像:三角剖分、n个叶节点树的种类、n个数字的进出栈、括号匹配、矩阵链乘等等都有卡特兰数的应用。
卡特兰数的通项公式:
$$
h(n) = C_{2n}^n - C_{2n}^{n-1}
$$
递推公式为:
$$
h(n) = h(n-1)*\frac{4n-2}{n+1}
$$
其实,求组合数时,当 n 很大的时候,计算也是个问题,好在有 Lucas定理 可以解决这事,当然以上这些与解决本题没啥关系。
本题做法是直接递归一下即可,每次放左括号(第16行)或右括号(第17行),递归的退出条件是放了n个左括号和n个右括号(第9行),剪枝条件是放的右括号数量大于左括号数量了,明显会造成非法串,直接返回退出(第13行)。
1 | class Solution { |
23、合并K个排序链表
合并的关键点在于如何快速找到当前最小值,最小堆可以帮我们快速实现这一点。
1 | /** |
24、两两交换链表中的节点
处理好两个指针之间的关系即可。
1 | class Solution { |
25、k个一组翻转链表
采用一个大小为 k 的栈来实现翻转。
1 | class Solution { |
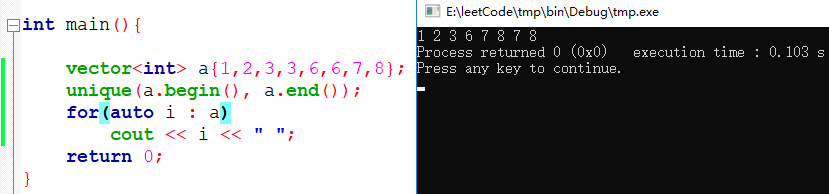
26、删除排序数组中的重复项
直接使用 STL 中的 unique 函数即可,unique 函数的具体说明如下:
iterator unique(iterator it_1,iterator it_2);
两个参数表示对容器中[it_1,it_2)范围的元素进行去重(注:区间是前闭后开,即不包含it_2所指的元素),返回值是一个迭代器,它指向的是去重后容器中不重复序列的最后一个元素的下一个元素。注意,unique函数的去重过程实际上就是不停的把后面不重复的元素移到前面来,也可以说是用不重复的元素占领重复元素的位置,而不是将重复的元素往后移动。
1 | class Solution { |
27、移除元素
双指针,执行调换过程即可,注意,如果前后调换后,nums[pFront] 可能依然等于 val,通过第11行的 continue语句巧妙的解决该问题。
1 | class Solution { |
28、实现strStr()
可以直接暴力,时间复杂度为$O(n^2)$。线性时间复杂度算法为 KMP 算法或 BM 算法。KMP 算法的关键是理解 next 数组的求解过程。
1 | class Solution { |
29、两数相除
使用移位操作模拟乘法,用减法代替除法。
1 | class Solution { |
30、串联所有单词的子串
words中单词长度固定,将s串按照固定长度切分保存进vector<string>中,之后使用两个map和滑动窗口实现匹配过程,详见代码:
1 | class Solution { |
